On the Pitfalls of Heteroscedastic Uncertainty Estimation with Probabilistic Neural Networks
@inproceedings{
seitzer2022on,
title={On the Pitfalls of Heteroscedastic Uncertainty Estimation with Probabilistic Neural Networks},
author={Maximilian Seitzer and Arash Tavakoli and Dimitrije Antic and Georg Martius},
booktitle={International Conference on Learning Representations},
year={2022},
url={https://openreview.net/forum?id=aPOpXlnV1T}
}一言でいうと: Beta-NLLは、Gaussian NLLが高分散予測点の平均勾配を弱めて難しい領域を無視する問題を避けるために、NLLをstop-gradient付き予測分散の 乗で重み付けする異分散回帰の損失である。
背景と目的 (Background & Objective)
Probabilistic neural networkで異分散回帰を学習するとき、平均 と分散 はGaussian negative log-likelihood (NLL)で同時に最適化されることが多い。
この論文が指摘する落とし穴は、Gaussian NLLでは平均の二乗誤差が で重み付けされる点である。 モデルがまだうまく平均を当てられない領域に大きな分散を出すと、その領域の平均勾配が小さくなり、以後ますます学習されにくくなる。
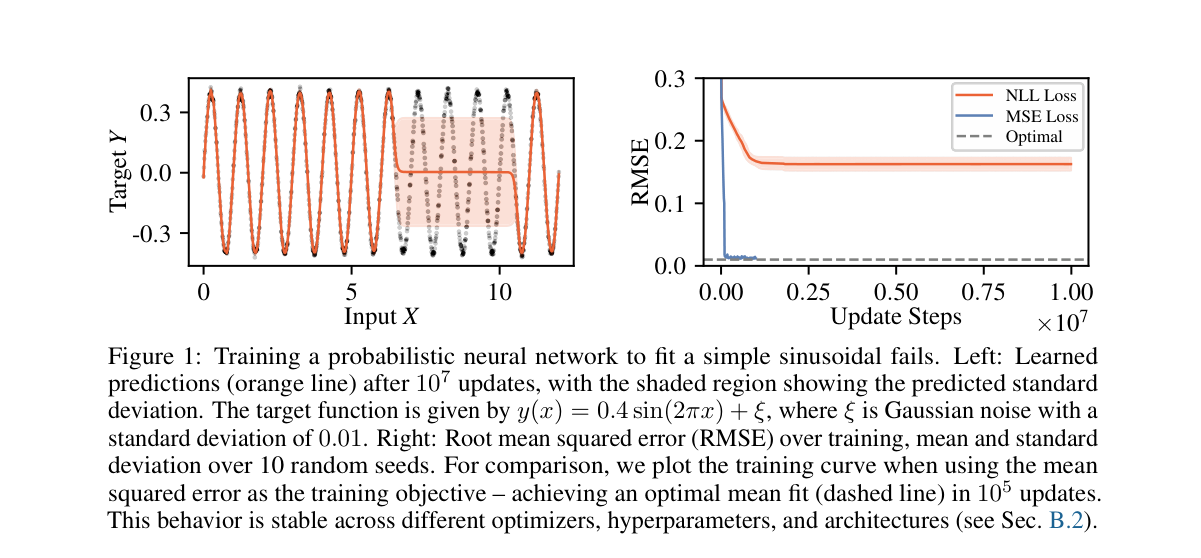
平均をMSEで学習する場合の目的関数は次である。
Gaussian NLLの平均と分散の勾配は次の形になる。
このため、NLLの学習は平均に関して、暗黙に次のような分布からサンプリングしてMSEを下げているように振る舞う。
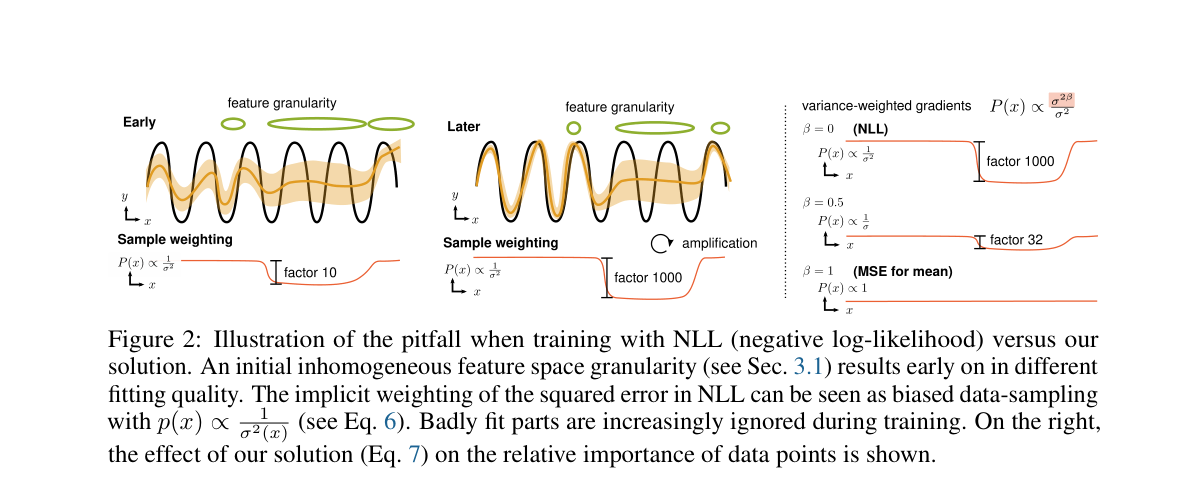
提案手法 (Proposed Method)
提案手法のBeta-NLLは、NLL全体を予測分散の 乗で重み付けする。
はstop-gradientを表す。 したがって、分散の 乗は重みとして使われるが、その重み自体を通じて分散ヘッドへ勾配を流さない。
この損失の勾配は次になる。
は通常のNLLに一致する。 では平均の勾配がMSEと同じになり、 は標準偏差の逆数による重み付けになる。 著者らは、追加計算なしでNLLの自己強化的な無視を弱められる実装として、 を実用的な初期値として扱う。
PyTorch実装では、分散重みだけをdetachする。
def beta_nll_loss(mean, variance, target, beta):
loss = 0.5 * ((target - mean) ** 2 / variance + variance.log())
if beta > 0:
loss = loss * variance.detach() ** beta
return loss.sum(axis=-1)実験と評価 (Experiments & Evaluation)
評価は、UCI_Regression_Datasets、ロボットダイナミクスのObjectSlideとFetch-PickAndPlace、VAEのMNISTとFashion-MNIST、単眼深度推定のNYUv2で行われる。 比較対象には通常のNLL、MSE、Student-t、natural parameterization、posterior network、xVAMP、VBEMが含まれる。
UCI回帰では、Beta-NLLは通常のNLLよりRMSEを改善し、MSEに近い平均精度を保ちやすい。 ただし、log likelihoodではStudent-tやxVAMPが優位なデータセットもある。
| 損失 | LL ties | RMSE ties | Concrete RMSE | Energy RMSE | Naval RMSE | Yacht RMSE | |
|---|---|---|---|---|---|---|---|
| NLL | 0.0 | 3 | 5 | 6.08 ± 0.65 | 2.25 ± 0.34 | 0.0021 ± 0.0006 | 1.22 ± 0.47 |
| Beta-NLL | 0.5 | 5 | 7 | 5.61 ± 0.65 | 1.12 ± 0.25 | 0.0006 ± 0.0002 | 2.35 ± 1.44 |
| Beta-NLL | 1.0 | 2 | 9 | 5.55 ± 0.77 | 1.54 ± 0.54 | 0.0004 ± 0.0000 | 2.08 ± 1.13 |
| MSE | - | - | 12 | 4.96 ± 0.64 | 0.92 ± 0.11 | 0.0004 ± 0.0001 | 0.78 ± 0.25 |
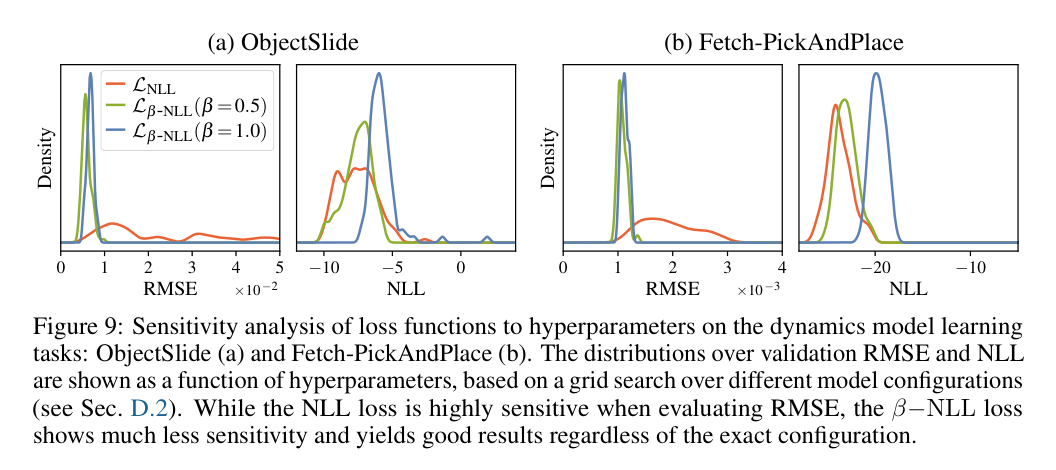
ロボットダイナミクスでは、 がRMSEとLLの両方で通常NLLを上回る。
| タスク | 損失 | RMSE | LL | |
|---|---|---|---|---|
| ObjectSlide | NLL | 0.0 | 0.0192 ± 0.006 | 7.97 ± 3.62 |
| ObjectSlide | Beta-NLL | 0.5 | 0.0064 ± 0.002 | 9.28 ± 0.75 |
| ObjectSlide | Beta-NLL | 1.0 | 0.0074 ± 0.001 | 6.58 ± 0.29 |
| Fetch-PickAndPlace | NLL | 0.0 | 0.00163 ± 0.00008 | 18.72 ± 7.32 |
| Fetch-PickAndPlace | Beta-NLL | 0.5 | 0.00096 ± 0.00002 | 24.68 ± 0.08 |
| Fetch-PickAndPlace | Beta-NLL | 1.0 | 0.00102 ± 0.00001 | 21.32 ± 0.07 |
VAEと深度推定でも、通常NLLよりBeta-NLLが平均精度を改善する傾向がある。 ただし、NYUv2では のRMSEはMSEに近い一方、LLは通常NLLより悪い。
| タスク | 損失 | RMSE | LL | |
|---|---|---|---|---|
| MNIST VAE | NLL | 0.0 | 0.237 ± 0.002 | 2116 ± 55 |
| MNIST VAE | Beta-NLL | 0.5 | 0.151 ± 0.003 | 2220 ± 25 |
| MNIST VAE | Beta-NLL | 1.0 | 0.152 ± 0.001 | 1706 ± 30 |
| Fashion-MNIST VAE | NLL | 0.0 | 0.170 ± 0.001 | 1940 ± 104 |
| Fashion-MNIST VAE | Beta-NLL | 0.5 | 0.125 ± 0.003 | 1639 ± 52 |
| Fashion-MNIST VAE | Beta-NLL | 1.0 | 0.138 ± 0.002 | 1142 ± 26 |
| NYUv2 depth | NLL | 0.0 | 0.3854 | -4.52 |
| NYUv2 depth | Beta-NLL | 0.5 | 0.3789 | -7.50 |
| NYUv2 depth | Beta-NLL | 1.0 | 0.3845 | -5.10 |
| NYUv2 depth | MSE | - | 0.3776 | - |
貢献と限界点 (Contributions & Limitations)
この論文の貢献は、Gaussian NLLの失敗を「予測分散による暗黙のサンプル重み付け」として説明し、単純な重み付けで平均学習の停止を緩和した点にある。 Beta-NLLは既存モデルの損失だけを差し替えればよく、アーキテクチャや推論手順を変えない。
限界は、Beta-NLLが真の予測分布を直接回復する原理的な保証を与えるわけではない点である。 特に、 を大きくすると平均推定はMSEに近づくが、log likelihoodや不確実性のキャリブレーションは悪化しうる。 このため、Beta-NLLは「平均精度を壊しにくい実用的なNLL補正」として扱うのが妥当であり、分布推定そのものを重視する場合はStudent-tやベイズ的手法との比較が必要になる。