Complex-Valued Variational Autoencoder
@inproceedings{Nakashika_2020,
series={interspeech_2020},
title={Complex-Valued Variational Autoencoder: A Novel Deep Generative Model for Direct Representation of Complex Spectra},
url={http://dx.doi.org/10.21437/Interspeech.2020-1964},
DOI={10.21437/interspeech.2020-1964},
booktitle={Interspeech 2020},
publisher={ISCA},
author={Nakashika, Toru},
year={2020},
month=Oct,
pages={2002-2006},
collection={interspeech_2020}
}一言でいうと: 複素値VAEは、音声の複素スペクトルから位相情報を落とさず潜在表現を学ぶために、入力、潜在変数、エンコーダ、デコーダをすべて複素値で定義したVAEである。
背景と目的 (Background & Objective)
標準的なVAEは、観測を実数ベクトルとして扱い、潜在変数に実ガウス分布を仮定する。 音声合成や音声符号化では、メルケプストラム、振幅スペクトル、メルスペクトルなどを入力にすることが多い。 しかし、これらの特徴量は本来の複素スペクトルから計算され、位相情報を失っている。
位相を捨てた特徴量から音声を復元する場合、Griffin-Lim法やボコーダが必要になる。 この復元過程は音質劣化の原因になり、複素スペクトルが持つ振幅と位相の構造を潜在表現に保持できない。 本論文の目的は、複素スペクトルを直接VAEで符号化し、位相情報をネットワーク全体で保つことである。
提案手法 (Proposed Method)
提案手法の**Complex-Valued Variational Autoencoder (CVAE)**は、複素値観測 と複素値潜在変数 を用いる。 エンコーダとデコーダのパラメータも複素値であり、通常のVAEのELBOを複素正規分布へ拡張する。
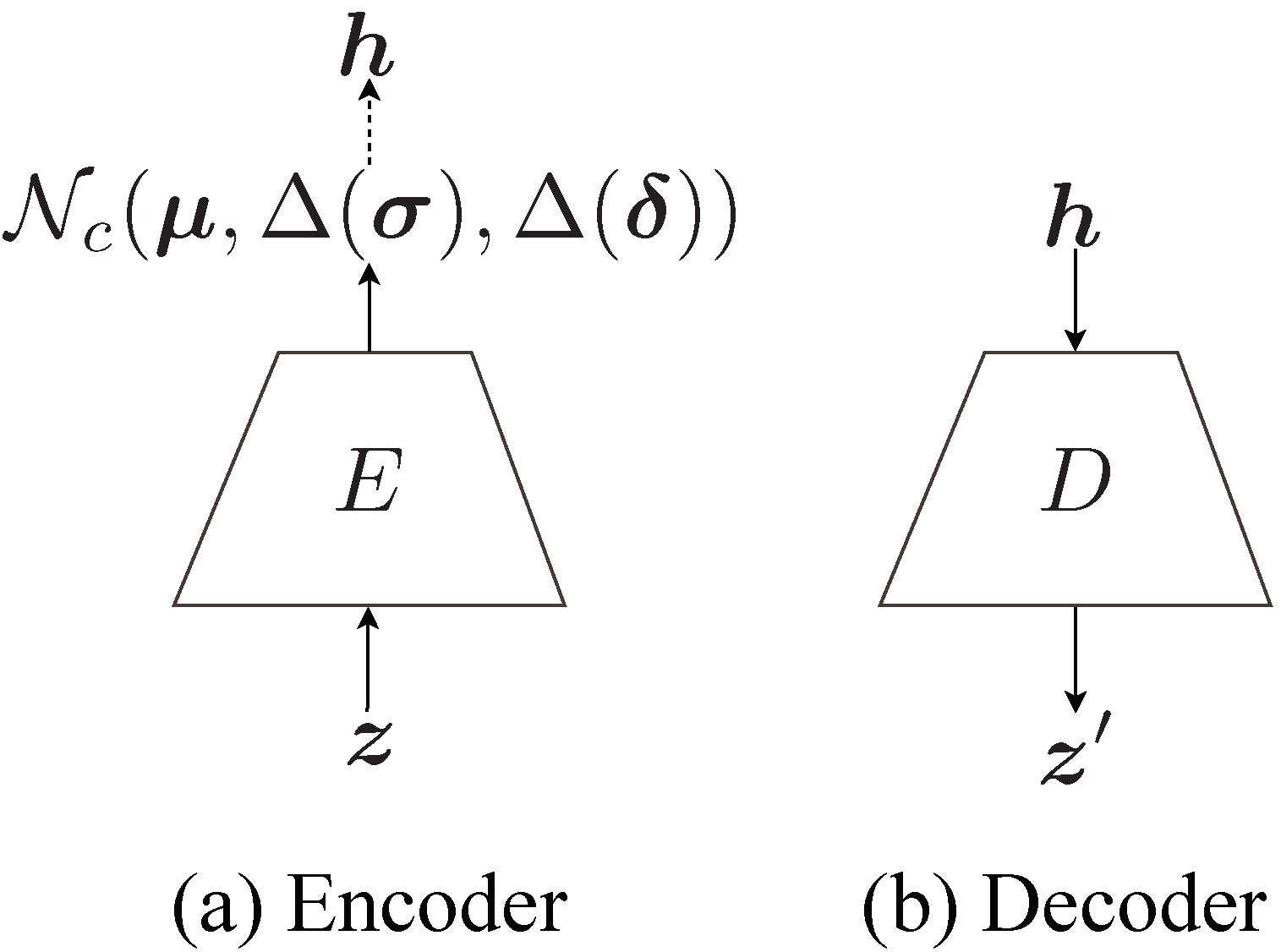
観測の条件付き分布は、複素正規分布として定義される。
本文の実装では簡単化のため、単位共分散とゼロ擬似共分散を仮定し、デコーダは平均 だけを出力する。 そのため、再構成項は定数を除いて次の二乗誤差になる。
潜在変数の近似事後分布は、対角共分散と対角擬似共分散を持つ複素正規分布である。
ここで、、、 はエンコーダ出力である。 事前分布は標準複素正規分布 とする。 KL項は閉形式で計算できる。
サンプリングを含むため、CVAEにも再パラメータ化が必要である。 論文は、複素潜在変数 を実部と虚部に分解し、擬似共分散 から実部と虚部の分散および相関を構成して、標準正規ノイズからサンプルを作る。
| 標準VAEの再パラメータ化 | CVAEの再パラメータ化 |
|---|---|
 | 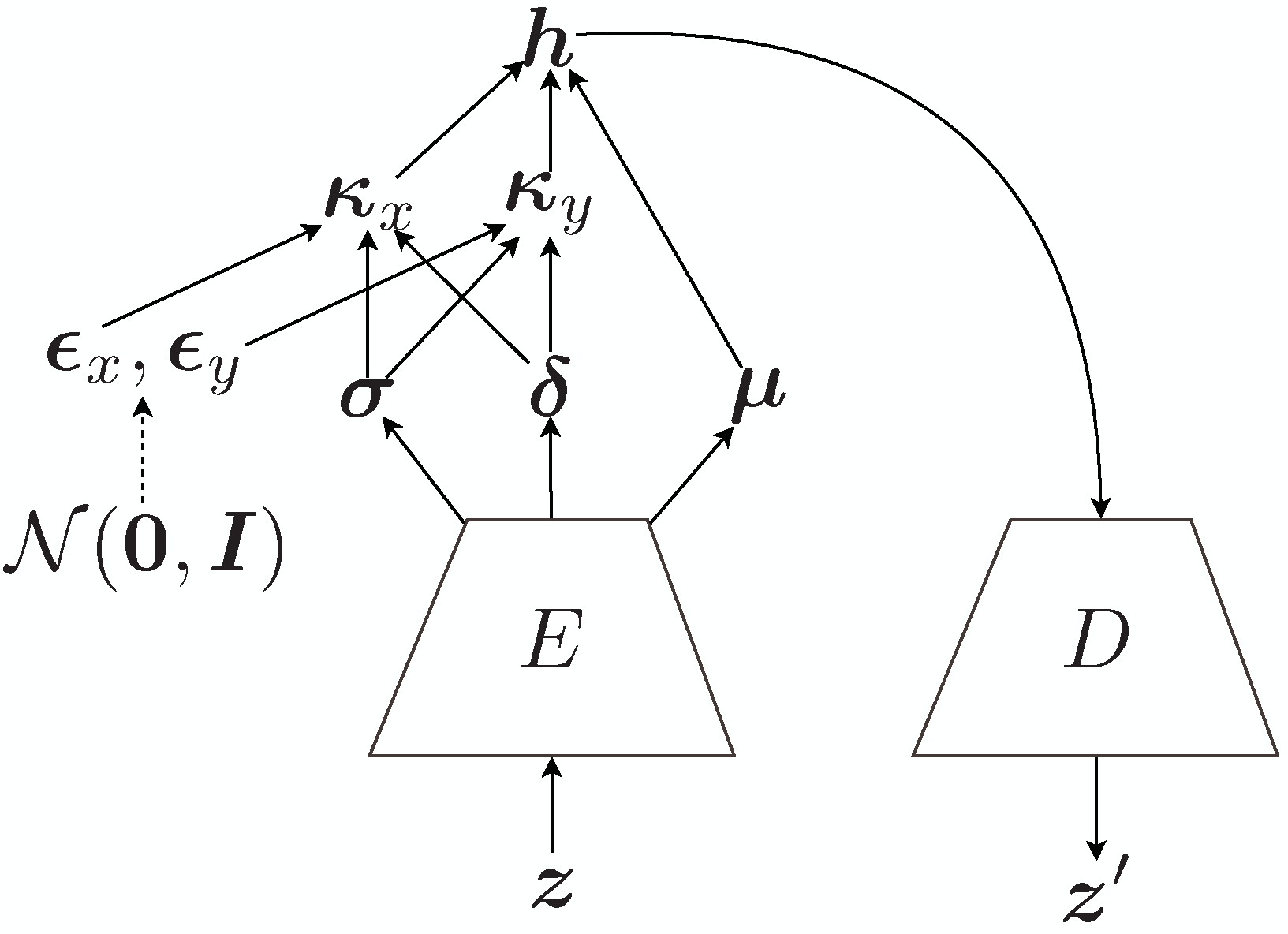 |
パラメータ更新にはWirtinger微分に基づく複素値勾配を用いる。
実験では、より効率のよい複素Adamを使っている。
実験と評価 (Experiments & Evaluation)
評価は、ATR音声コーパス set B の女性話者FTKによる音声で行われた。 50文を訓練、53文をテストに使い、20 kHz音声を16 kHzへダウンサンプリングした。 STFTはwindow長512、hop長64で、255次元の複素スペクトルを入力特徴量とする。
比較対象は、振幅スペクトルを入力してGriffin-Limで復元するVAE(GL)と、複素スペクトルの実部・虚部を結合した実数ベクトルを入力するVAE(R+I)である。 CVAEとVAE(R+I)は、復元した複素スペクトルからinverse STFTとoverlap-addで音声を復元する。
| 項目 | CVAE | VAE(R+I) | VAE(GL) |
|---|---|---|---|
| 入力特徴量 | 複素スペクトル | 複素スペクトルの実部・虚部 | 振幅スペクトル |
| 音声復元 | inverse STFT + OLA | inverse STFT + OLA | Griffin-Lim |
| エポック数 | 80 | 540 | 290 |
| optimizer | CAdam (0.0001) | Adam (0.001) | Adam (0.001) |
| encoder | 255-100-[50,50,50] | 510-200-[100,100] | 255-100-[50,50] |
| decoder | 50-100-255 | 100-200-510 | 50-100-255 |
結果は、CVAEが客観評価と主観評価の両方で最も良い。
| 手法 | PESQ | MOS |
|---|---|---|
| VAE(GL) | 1.90 | |
| VAE(R+I) | 1.80 | |
| CVAE | 2.44 | |
| CVAE without | 2.39 | - |
| Original | - |
再構成スペクトルの比較でも、CVAEはフォルマントや高周波の細かい構造を比較的よく保っている。

貢献と限界点 (Contributions & Limitations)
貢献は、VAEの入力だけでなく、潜在変数、事後分布、事前分布、ネットワークパラメータまでを複素値で定義した点である。 この設計により、複素スペクトルの位相情報をVAE内部で保持し、Griffin-Limのような位相復元に依存しない音声再構成を可能にした。
限界は、実験が単一話者の小規模なanalysis-by-synthesisに限られる点である。 モデルも全結合層中心であり、畳み込み、スキップ接続、深いアーキテクチャを入れた場合の性能は未検証である。 また、PESQとMOSでは明確な改善があるものの、現代的なニューラルボコーダや大規模音声コーデックとの比較ではない。