Poisson Variational Autoencoder
@inproceedings{NEURIPS2024_4f3cb957,
author = {Vafaii, Hadi and Galor, Dekel and Yates, Jacob},
booktitle = {Advances in Neural Information Processing Systems},
doi = {10.52202/079017-1426},
editor = {A. Globerson and L. Mackey and D. Belgrave and A. Fan and U. Paquet and J. Tomczak and C. Zhang},
pages = {44871--44906},
publisher = {Curran Associates, Inc.},
title = {Poisson Variational Autoencoder},
url = {https://proceedings.neurips.cc/paper_files/paper/2024/file/4f3cb9576dc99d62b80726690453716f-Paper-Conference.pdf},
volume = {37},
year = {2024}
}一言でいうと: PoissonVAEは、VAEの潜在変数を連続GaussianではなくPoisson spike countsとして扱うために、Poisson reparameterization trickと予測符号化的なrate parameterizationを導入する離散潜在VAEである。
背景と目的 (Background & Objective)
標準的なVAEは、潜在変数にGaussianなどの連続分布を使う。 しかし、生物学的ニューロンはスパイク数として離散的に発火し、短い時間窓ではPoisson-likeな統計を示すことが多い。 この論文は、perception as inference、rate coding、predictive coding、sparse codingをVAEの枠組みで結び、潜在変数を離散spike countsとして扱うPoissonVAEを提案する。

提案手法 (Proposed Method)
P-VAEでは、潜在変数 をPoisson分布からサンプルされるspike countsとして扱う。 posteriorとpriorはそれぞれ次で定義される。
は学習可能なprior firing ratesであり、 はencoderが出す入力依存のdeviationである。 この残差的parameterizationにより、feedbackの期待 とfeedforwardのずれ が要素ごとの積で結びつく。
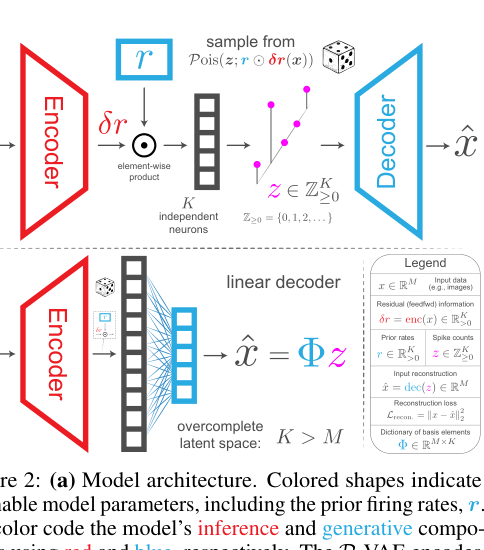
Poisson分布は離散分布なので、そのままでは通常のreparameterization trickを使えない。 P-VAEはhomogeneous Poisson processの待ち時間表現を使い、Exponential分布からinter-event timesをサンプルし、累積到着時刻が単位時間内に入るかをsoft indicatorで近似する。

はtemperatureであり、 でhard thresholdに近づく。 訓練時は のrelaxed Poissonを使い、テスト時は にして整数Poisson samplesを使う。
P-VAEの目的関数は次である。
KL項 はfiring ratesを罰するため、代謝コストやsparse codingのactivity penaltyに似た役割を持つ。 線形decoder とovercomplete latent space を仮定すると、P-VAEはamortized sparse codingとして解釈できる。
公式実装メモ
公式実装は hadivafaii/PoissonVAE で公開されている。
Poisson reparameterizationは base/distributions.py の Poisson.rsample() に実装されている。
x = self._exp.rsample((self.n_exp,))
times = torch.cumsum(x, dim=0)
logits = (1 - times) / self.temp
indicator = fn(logits)
z = indicator.sum(0).to(dtype=self.rate.dtype)P-VAE本体では、encoder出力 log_dr をprior log-rate log_r に加え、posterior rateを としてPoisson分布へ渡す。
これは論文の に対応する。
log_r = self.log_rate.expand(len(x), -1)
log_dr = self.encode(x)
dist = self.Dist(
log_rate=softclamp_upper(log_r + log_dr, 5.0),
indicator_approx=self.cfg.indicator_approx,
n_exp=self.n_exp,
temp=t,
)出典: main/vae.py
KL項も閉形式で実装されている。
log_dr は なので、1 + exp(log_dr) * (log_dr - 1) は と同じ形である。
def loss_kl(self, log_dr):
log_r = self.log_rate.expand(len(log_dr), -1)
f = 1 + torch.exp(log_dr) * (log_dr - 1)
kl = torch.exp(log_r) * f
return kl出典: main/vae.py
実験と評価 (Experiments & Evaluation)
比較対象は、PoissonVAE、Categorical VAE、Gaussian VAE、Laplace VAEである。 実験は、van_Hateren_Dataset、CIFAR10から作ったCIFAR16×16、MNISTで行われる。
Poisson reparameterizationの評価では、線形decoderで計算できるexact gradientsと、Monte Carlo samplingやstraight-through estimatorを比較する。 P-VAEのMonte Carlo推定はexact gradientsに近い一方、straight-through estimatorは大きく性能を落とす。
| Model | Gradient | van Hateren lin | van Hateren conv | CIFAR16×16 lin | CIFAR16×16 conv | MNIST lin | MNIST conv |
|---|---|---|---|---|---|---|---|
| P-VAE | Exact | 0.6 ± .5 | 0.7 ± .1 | 0.0 ± .1 | 0.5 ± .1 | 0.1 ± .1 | 0.9 ± .5 |
| P-VAE | Monte Carlo | 0.1 ± .1 | 7.3 ± .1 | 0.0 ± .0 | 9.1 ± .1 | 0.5 ± .6 | 8.1 ± .3 |
| P-VAE | Straight-through | 0.0 ± .1 | 10.5 ± .1 | 0.2 ± .0 | 12.5 ± .1 | 0.7 ± .4 | 11.8 ± .2 |
| G-VAE | Exact | 0.1 ± .1 | 0.1 ± .1 | 0.0 ± .1 | 0.1 ± .1 | 0.1 ± .2 | 0.4 ± .1 |
| G-VAE | Monte Carlo | 0.0 ± .0 | 0.0 ± .0 | 0.0 ± .0 | 0.0 ± .0 | 0.1 ± .2 | 0.3 ± .1 |
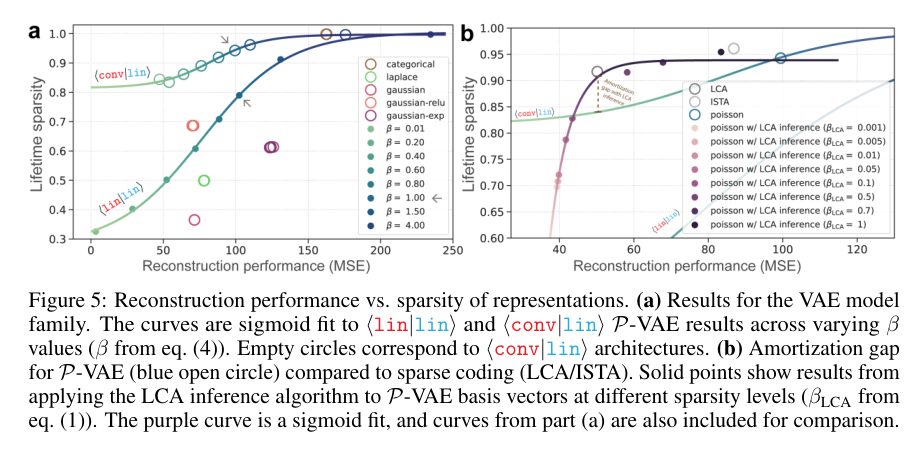
Sparse codingとの比較では、P-VAEはGabor-likeなbasis elementsを学習し、LCAやISTAに似た辞書を得る。

posterior collapseの評価では、P-VAEはcontinuous VAEより多くのactive neuronsを保つ。
| Model | van Hateren linear | van Hateren conv | CIFAR16×16 linear | CIFAR16×16 conv | MNIST linear | MNIST conv |
|---|---|---|---|---|---|---|
| P-VAE | 0.984 ± .011 | 0.819 ± .041 | 0.999 ± .002 | 0.928 ± .045 | 0.537 ± .008 | 0.426 ± .011 |
| L-VAE | 0.188 ± .000 | 0.222 ± .003 | 0.193 ± .003 | 0.230 ± .000 | 0.027 ± .000 | 0.034 ± .002 |
| G-VAE | 0.218 ± .003 | 0.246 ± .000 | 0.105 ± .008 | 0.246 ± .000 | 0.027 ± .000 | 0.031 ± .000 |
下流分類では、MNISTの5,000 validation samplesをtrain/testに分け、KNNで少数ラベル時の性能を比較する。 の潜在次元では、P-VAEは で0.815、G-VAEは0.705であり、G-VAEが同程度の精度に達するには が必要になる。
| Model | KNN N=200 | KNN N=1,000 | KNN N=5,000 | Shattering dim. |
|---|---|---|---|---|
| P-VAE | 0.815 ± .002 | 0.919 ± .001 | 0.946 ± .017 | 0.797 ± .009 |
| C-VAE | 0.705 ± .002 | 0.800 ± .002 | 0.853 ± .040 | 0.795 ± .006 |
| L-VAE | 0.757 ± .003 | 0.869 ± .002 | 0.924 ± .028 | 0.751 ± .008 |
| G-VAE | 0.673 ± .003 | 0.813 ± .002 | 0.891 ± .033 | 0.758 ± .007 |
| G-VAE +relu | 0.694 ± .003 | 0.817 ± .003 | 0.877 ± .045 | 0.762 ± .007 |
| G-VAE +exp | 0.642 ± .003 | 0.784 ± .002 | 0.863 ± .032 | 0.737 ± .008 |
貢献と限界点 (Contributions & Limitations)
主な貢献は、Poisson-distributed latent variablesをVAEに組み込み、離散spike countsを微分可能に扱うreparameterization trickを示した点である。 また、KL項が自然にfiring-rate penaltyになり、線形decoderではamortized sparse codingと対応することを示している。
限界は、Poisson spike countsが短時間窓の神経発火の近似であり、皮質活動の長時間窓ではPoissonから外れる場合がある点である。 さらに、現在のencoderではLCA/ISTAに対するamortization gapが残り、P-VAEのdictionaryを使ってLCA inferenceを行うとMSEが改善する。 このため、P-VAEの潜在表現と辞書は有望だが、推論ネットワークの表現力や反復推論との統合は未解決である。