Faithful Heteroscedastic Regression with Neural Networks
@InProceedings{pmlr-v206-stirn23a,
title = {Faithful Heteroscedastic Regression with Neural Networks},
author = {Stirn, Andrew and Wessels, Harm and Schertzer, Megan and Pereira, Laura and Sanjana, Neville and Knowles, David},
booktitle = {Proceedings of The 26th International Conference on Artificial Intelligence and Statistics},
pages = {5593--5613},
year = {2023},
editor = {Ruiz, Francisco and Dy, Jennifer and van de Meent, Jan-Willem},
volume = {206},
series = {Proceedings of Machine Learning Research},
month = {25--27 Apr},
publisher = {PMLR},
pdf = {https://proceedings.mlr.press/v206/stirn23a/stirn23a.pdf},
url = {https://proceedings.mlr.press/v206/stirn23a.html}
}一言でいうと: Faithful Heteroscedastic Regressionは、異分散モデルに分散ヘッドを足しても平均予測を壊さないために、平均をSSEで、分散をstop-gradient付きGaussian NLLで分けて学習する方法である。
背景と目的 (Background & Objective)
異分散回帰では、条件付き分布を
として、平均 と分散・共分散 をニューラルネットワークで同時に推定する。 標準的な方法はガウス負対数尤度(NLL)を最小化する。
しかし、単変量の場合の勾配は
となる。 このため、予測分散が大きい点ほど平均学習の信号が弱まり、平均誤差を高分散で説明してしまう “rich-get-richer” 的な失敗が起きる。
本論文の目的は、異分散モデルが分散ヘッドを持つことで、同じ平均表現能力を持つ平均のみのモデルより悪い平均推定をしてしまう問題を防ぐことである。 著者らは、異分散モデルの平均部分だけを取り出した mean-only baseline と比べ、平均推定が悪化しない性質を faithfulness と定義する。
提案手法 (Proposed Method)
論文は、ヘテロスケダスティックネットワークを3つの部分に分ける。
- 共有表現学習器:
- 平均ヘッド:
- 共分散ヘッド:

提案は2つの変更からなる。
| 提案 | 内容 | 役割 |
|---|---|---|
| Proposal 1 | を でスケールする | NLLの平均勾配をSSEの平均勾配に一致させる |
| Proposal 2 | が共有幹 に流れないよう stop-gradient する | 分散ヘッドが共有表現を平均推定から逸らすのを防ぐ |
この2つは、次の損失として実装できる。
は stop-gradient を表す。 ここで は正規分布からサンプリングする操作ではなく、観測値 に対する正規分布の対数密度を評価する操作である。 したがって第2項はGaussian NLLであり、stop-gradientにより主に分散ヘッド の学習信号として使われる。 第1項は平均をSSEで学習し、第2項は平均と共有表現を定数扱いして分散ヘッドだけをNLLで学習する。
PyTorchでの実装メモ
PyTorchでは、stop-gradient は .detach() で実装できる。
重要なのは、分散ヘッド をdetachするのではなく、分散ヘッドへの入力である共有表現 と、NLL内の平均 をdetachする点である。
import torch
import torch.nn.functional as F
def faithful_heteroscedastic_loss(model, x, y):
# model.trunk: x -> z
# model.mean_head: z -> mu
# model.logvar_head: z -> log_sigma2
z = model.trunk(x)
mu = model.mean_head(z)
# Mean/trunk are trained only by this SSE term.
mean_loss = 0.5 * F.mse_loss(mu, y, reduction="none")
# Variance head is trained by Gaussian NLL.
# Detach z and mu so this NLL term does not update trunk or mean_head.
logvar = model.logvar_head(z.detach())
inv_var = torch.exp(-logvar)
residual2 = (y - mu.detach()).pow(2)
var_loss = 0.5 * (logvar + residual2 * inv_var)
return (mean_loss + var_loss).mean()このコードでは、var_loss から model.logvar_head には勾配が流れる。
一方で、z.detach() により model.trunk には流れず、mu.detach() により model.mean_head にも流れない。
つまり「平均用のSSE」と「分散用のstop-gradient付きGaussian NLL」を足して同時に最適化している。
Theorem 1 は、この損失で勾配ベース最適化を行うと、異分散モデルの平均ヘッドと共有幹の更新が、mean-only baseline をSSEで学習した場合と同一になることを示す。 したがって、同じ乱数条件のもとでは、平均推定について faithfulness が保証される。
実験と評価 (Experiments & Evaluation)
収束挙動
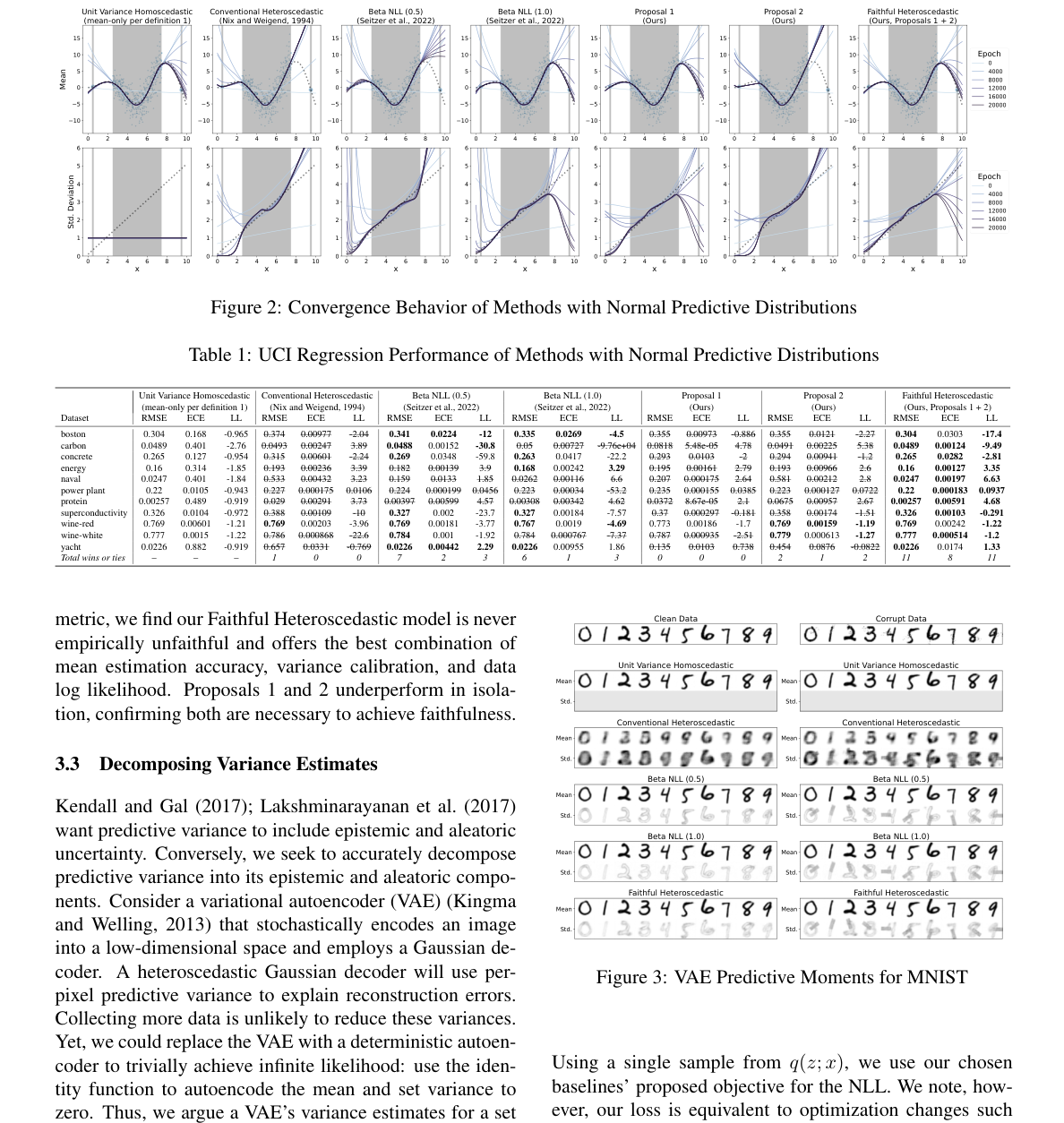
合成データでは、、 に孤立点を加え、各手法の平均・分散の収束を比較する。 標準NLLの異分散モデルは、孤立点の大きな平均誤差を分散増大で説明し、平均が収束しない。 Faithful Heteroscedastic は、平均のみモデルと同様に孤立点へ収束しつつ、分散も推定する。
UCI回帰
UCI回帰データセットでは、10-fold cross validation により全点にheld-out予測を作り、RMSE、Expected Calibration Error(ECE)、log likelihood(LL)を評価する。
Table 1 の集計では、Faithful Heteroscedastic が最も安定している。
| 手法 | RMSE wins/ties | ECE wins/ties | LL wins/ties | コメント |
|---|---|---|---|---|
| Conventional Heteroscedastic | 1 | 0 | 0 | 複数データで平均推定がmean-only baselineより悪化 |
| Beta NLL (0.5) | 7 | 2 | 3 | 平均改善はあるがfaithfulness保証はない |
| Beta NLL (1.0) | 6 | 1 | 3 | 平均は改善しやすいが分散較正に課題 |
| Proposal 1 only | 0 | 0 | 0 | 単独では不十分 |
| Proposal 2 only | 2 | 1 | 2 | 単独では不十分 |
| Faithful Heteroscedastic | 11 | 8 | 11 | 平均推定、較正、LLの総合性能が最良 |
VAEとCRISPR-Cas13
VAE実験では、MNIST/Fashion-MNISTの再構成に対し、clean/corruptデータで平均・分散推定を比較する。 Faithful Heteroscedastic は、他手法が平均推定でunfaithfulになる設定でも、RMSE、ECE、LLで全4条件のwins/tiesを得る。
CRISPR-Cas13効率予測では、replicate と平均化データを使い、予測分散からaleatoric成分を取り出す応用を示す。 著者らは、Cas13の配列依存な異分散性をモデル化した初の例だと述べる。
貢献と限界点 (Contributions & Limitations)
主な貢献は、異分散NLLの最適化問題を「平均のみモデルに対するfaithfulness」として定式化し、2つの簡単な勾配変更で平均推定の悪化を理論的に防いだ点である。 特に、既存のNLL学習、-NLL、単独のstop-gradientでは保証できない平均推定の同一性を、SSE項とstop-gradient付き分散NLLの組み合わせで実現する。
限界は、予測分布が基本的にガウスであり、重尾ノイズや分布ミスマッチそのものを扱う手法ではない点である。 また、faithfulness は平均推定に関する保証であり、分散推定の真値回復やキャリブレーションを常に保証するものではない。 分散ヘッドは平均・共有表現から切り離して学習されるため、分散学習が必要とする表現と平均学習が必要とする表現が大きく異なる場合には、表現共有の制約が残る。
ComplexOrliczとの関係
ComplexOrlicz撤回プレプリントは、本論文を「faithful training」として参照し、stop-gradientにより共有幹への分散勾配を遮断する方法だと位置づけている。 ただし ComplexOrlicz は撤回済みプレプリント由来であり、主張の信頼性は本論文とは分けて扱う必要がある。